会話型AIをビジネスに導入する動きが急速に広がっています。しかし、実用的な会話型AIを構築するには、プロンプトの書き方やナレッジの与え方など、複雑な設計ノウハウの理解が欠かせません。本記事では、会話型AI構築プラットフォーム「miibo(ミーボ)」を使って、精度の高いエージェントを設計するためのプロンプト設計手法を体系的に解説します。
miiboのプロンプト設計を理解すれば、専門知識がなくても実用的な会話型AIを構築できます。miiboは、ノーコードでChatGPTやClaudeなどのLLMをカスタマイズできる会話型AI構築プラットフォームです。このmiiboのプロンプトは、ベースプロンプト・前提データプロンプト・会話履歴・追記プロンプトの4要素で構成されています。4要素の理解にもとづき、プロンプトエディタ・ナレッジデータストア・検索クエリー生成プロンプトを適切に組み合わせれば、エージェントの応答精度を大幅に向上できます。
miiboの概要と提供価値
miiboは、だれでもかんたんに会話型AIを構築できるノーコードプラットフォームです。AI開発に必要な技術的ハードルを取り除き、プログラミング不要でAIソリューションを爆速開発できる環境を提供しています。
miiboの最大の価値は、ノーコードで爆速開発できる点にあります。ChatGPTやClaudeといった代表的なLLMを自在にカスタマイズでき、カスタマーサクセス、パーソナライズ対応、キャラクター活用など、多様なAIアプリケーションを実現できます。プログラミングスキルが不要のため、AI初心者から本格的な開発を望むデベロッパーまで、幅広い層に対応可能です。
miiboを運営するのは株式会社miiboです。株式会社miiboは2023年4月7日に設立され、会話型AIの社会実装を推進する事業を展開しています。「me + bot」の意味が社名に込められており、だれもが自分自身をAI化できる環境の創出を目指しています。
miiboで実現できることは多岐にわたります。具体的には、プログラミング不要でのAI開発、様々なLLMのカスタマイズ(LLMフラット)、様々なサービスとの連携(Connect Everything構想)、作成したAIの組み込み、開発と運用コストの最小化、パーソナライズされた会話の実現です。
miiboのプロンプトを構成する4つの要素

miiboのプロンプトは、4つの構成要素から成り立っています。4つの構成要素とは、ベースプロンプト・前提データプロンプト・会話履歴・追記プロンプトです。4要素の理解は、精度の高いエージェント構築の出発点になります。
ベースプロンプトは、エージェントの基本動作を定義する中核部分です。プロンプトエディタに記述した内容がここに格納され、役割・目的・制約条件など、エージェントの応答を根本から制御します。
前提データプロンプトは、エージェントに専門知識を与える領域です。ナレッジデータストアに登録された情報が、ユーザーの発話に応じて検索され、この領域に「前提データ」として追加されます。
会話履歴は、ユーザーとエージェントの過去のやりとりを保持する領域です。会話の文脈を維持することで、一貫性のある自然な対話を実現します。
追記プロンプトは、プロンプト全体の最後に配置される領域です。200文字以内の制約がある代わりに、最も守ってほしい指示を配置することで、応答精度を引き上げられます。
プロンプトエディタでベースプロンプトを書く方法
プロンプトエディタでは、エージェントにわかりやすい記述をすることが重要です。わかりやすい記述のポイントは、「目的と整合性のある文章構成」「統一性のある文章構造」「シンプルな文」の3つです。
目的と整合性のある文章構成とは、モレやダブりのない文章構成です。作成の手順は3ステップで進めます。最初のステップで、エージェントをユーザーに提供する目的を明確化し、エージェントの紹介文と一致させます。次のステップで、目的にそって内容(前提条件・役割・ターゲット・行動方針・制約条件など)を具体化します。最後のステップで、目的と内容を「それはなぜ、どのように」「だからなに」でつなげてチェックし、モレやダブりを検証します。
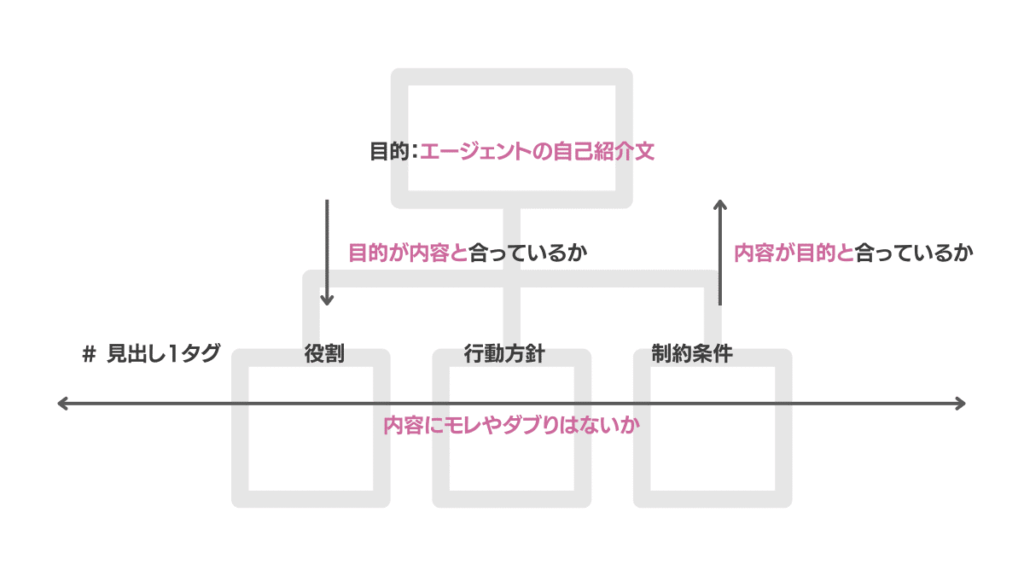
統一性のある文章構造は、内容の理解を助けます。すべての内容を同じフォーマットで書くと、読み手のストレスが減り、内容に集中できます。また、ベースプロンプトの階層は「#(見出し1)」「##(見出し2)」の2階層までに抑えることが大切です。2階層に抑えると、プロンプトの理解が進みます。
シンプルな文は、内容が伝わりやすい文です。シンプルな文の条件は、単文であることと、5W1Hがまとまっていることの2つです。単文とは述語がひとつの文であり、主語を明確に書くとエージェントの挙動が安定します。
ナレッジデータストアで専門知識を与える
ナレッジデータストアは、AIに専門知識を保持させるためのデータベースです。登録した情報はRAG(Retrieval-Augmented Generation:検索拡張生成)の仕組みで活用され、エージェントの応答に専門性を加えます。ナレッジデータストアを適切に設計すれば、ハルシネーションを減らし、最新で信頼できる情報にもとづく応答を実現できます。
ナレッジデータストアの情報は、4つのステップでエージェントの応答に反映されます。最初にユーザーが発話し、次に検索クエリーが生成されます。生成された検索クエリーでナレッジデータストアが検索され、スコア上位の情報が前提データプロンプトに追加されます。
ナレッジデータストアの精度を上げるポイントは3つあります。3つのポイントとは、ベースプロンプトによる前提データの制御、プロンプト全体の階層構造の統一、データ入稿のベストプラクティスです。
ベースプロンプトによる前提データの制御では、制約条件を明示します。前提データにない情報を聞かれたときの応答も指定し、エージェントの暴走を防ぎます。
プロンプト全体の階層構造の統一では、役割分担を明確にします。ベースプロンプトは「#」「##」の2階層までとし、ナレッジデータストアの情報には「#」「##」を使用しません。この役割分担により、ベースプロンプトの挙動が安定します。
データ入稿のベストプラクティスでは、データの粒度と形式を揃えます。1つのデータ入稿に1つの話題を割り当て、すべてのデータフォーマットを統一します。

検索クエリー生成プロンプトを最適化する
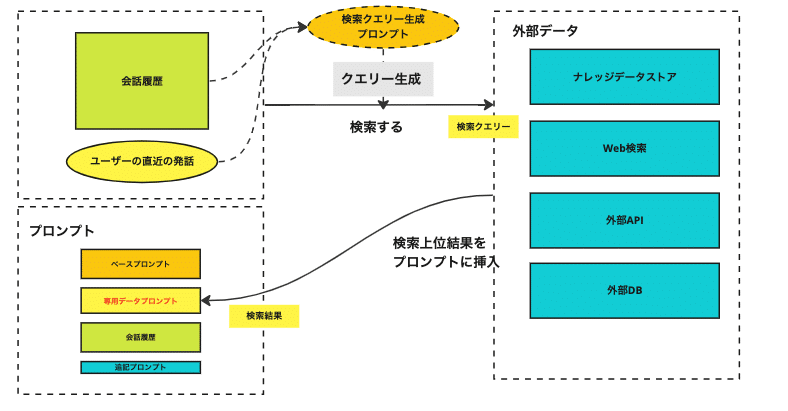
検索クエリー生成プロンプトは、RAGで利用する検索クエリーを生成するためのプロンプトです。このプロンプトを最適化すれば、ナレッジデータストアから適切な情報を引き出し、回答精度を向上できます。miiboにはデフォルトのプロンプトが用意されており、1クリックで導入できます。
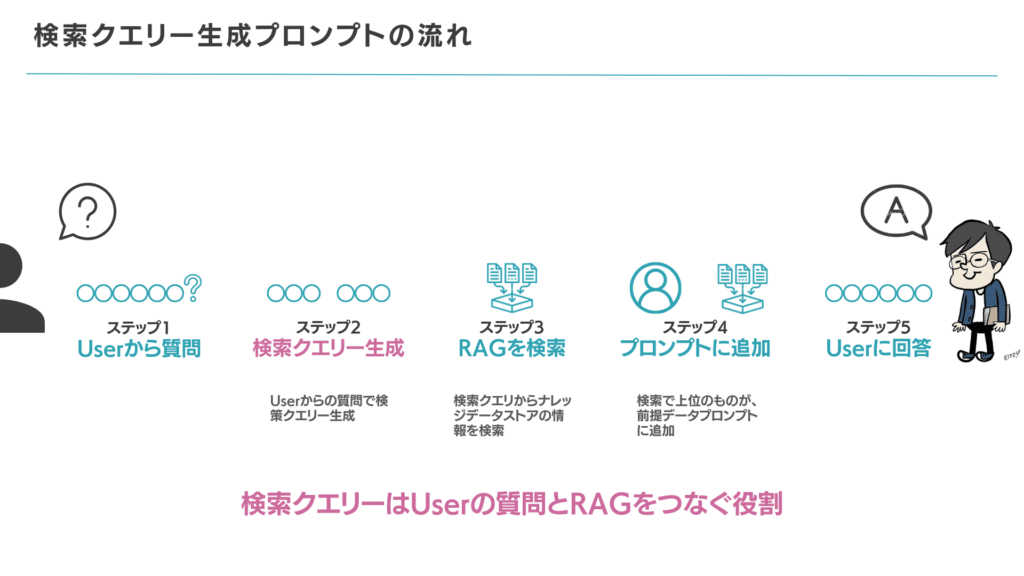
検索クエリー生成の流れは3ステップです。ユーザーが質問し、検索クエリーが生成され、RAGが検索されます。検索クエリーは、ユーザーの質問とRAGをつなぐ橋渡しの役割を担います。
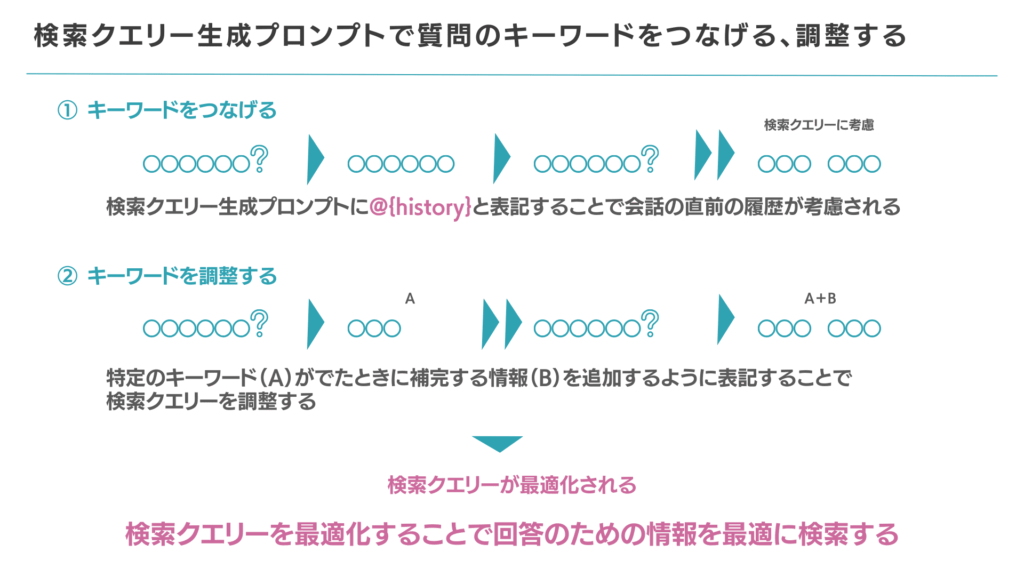
検索クエリーを最適化する手法は3つあります。3つの手法とは、会話履歴の考慮、特定キーワードの挿入、会話ログにもとづく調整です。
会話履歴の考慮では、@{history}をプロンプトに記述します。@{history}の記述により、会話のやりとりでキーワードをつなげ、ユーザーのニーズを絞り込めます。
特定キーワードの挿入では、必ず含めたいキーワードをプロンプトに直接書きます。たとえば「必ずmiiboというキーワードを出力してください」と記述すれば、検索クエリーに必ず「miibo」が含まれます。
会話ログにもとづく調整では、レポート機能を活用します。実際の会話で生成された検索クエリーを確認し、プロンプトを継続的に改善します。
ClaudeとXMLタグで精度をさらに高める
Claudeを活用する最大のメリットは、XMLタグでベースプロンプトとRAGの情報を明確に区別できる点です。AnthropicのClaudeは、XMLタグを含むプロンプトに特に精通しているため、構造化されたプロンプトで応答精度が向上します。XMLタグを使えば、ナレッジデータストアの前提データにある「#見出しタグ」の階層を意識する必要がなくなります。
Claudeには5つの強みがあります。5つの強みとは、倫理的AI設計、透明性と誠実さ、複雑な問題解決能力、ユーザー中心の対話、継続的な学習と適応です。特にユーザー中心の対話は、パーソナライズされた会話ができるmiiboとの相性が良好です。
miiboのベースプロンプトで使用する主要なXMLタグは以下のとおりです。<objective>で目的を定義し、<role>で役割を割り当てます。<context>で背景情報を提供し、<instructions>で詳細な指示を含めます。<constraints>で制約条件を指定し、<output_format>で出力形式を指定します。<example>で具体例を提供し、<error_handling>で予期せぬ状況への対処を指定します。
miibo独自の長文データ配置テクニックを使えば、Claudeの性能を最大化できます。Anthropicのガイドによると、長文データをプロンプトの上部に配置すると応答品質が最大30%向上します。具体的な手順は、ベースプロンプトの最後に<input>タグを追加し、追記プロンプトの先頭に</input>を書くことです。この手順により、前提データプロンプトと会話履歴を<input>タグで囲み、長文データを上部に配置できます。追記プロンプトは200文字以内のため、最も守ってほしい指示を厳選して記述します。
よくあるご質問
Q
miiboとは何ですか?
だれでも簡単に会話型AIを構築できるノーコードプラットフォームです。ChatGPTやClaudeなどのLLMをカスタマイズし、高速でAIソリューションを開発できます。
Q
miiboのプロンプトを構成する要素は何ですか?
ベースプロンプト・前提データプロンプト・会話履歴・追記プロンプトの4つです。
Q
ナレッジデータストアとは何ですか?
AIに専門知識を与えるためのデータベースです。登録した情報はRAGの仕組みで活用され、エージェントの応答に専門性を加えます。
Q
検索クエリー生成プロンプトの役割は何ですか?
RAGで利用する検索クエリーを生成するプロンプトです。最適化することで、ナレッジデータストアから適切な情報を引き出せます。
Q
ClaudeでXMLタグを使用するメリットは何ですか?
ベースプロンプトとRAGのデータを明確に区別できる点です。「#見出しタグ」の階層を意識せず、LLMが指示だけに集中できます。
まとめ:miiboで精度の高い会話型AIを構築しよう
miiboを活用すれば、だれでもかんたんに精度の高い会話型AIを構築できます。重要なのは、プロンプトの4構成要素(ベースプロンプト・前提データプロンプト・会話履歴・追記プロンプト)を理解することです。4要素の理解のうえで、プロンプトエディタ・ナレッジデータストア・検索クエリー生成プロンプトを適切に設計すれば、エージェントの応答精度は飛躍的に向上します。Claudeを活用する場合は、XMLタグの使用でさらに精度を高められます。miiboは無料で利用できるため、本記事のテクニックを実践し、実用的な会話型AI構築に挑戦してみてください。
コメントを残す